
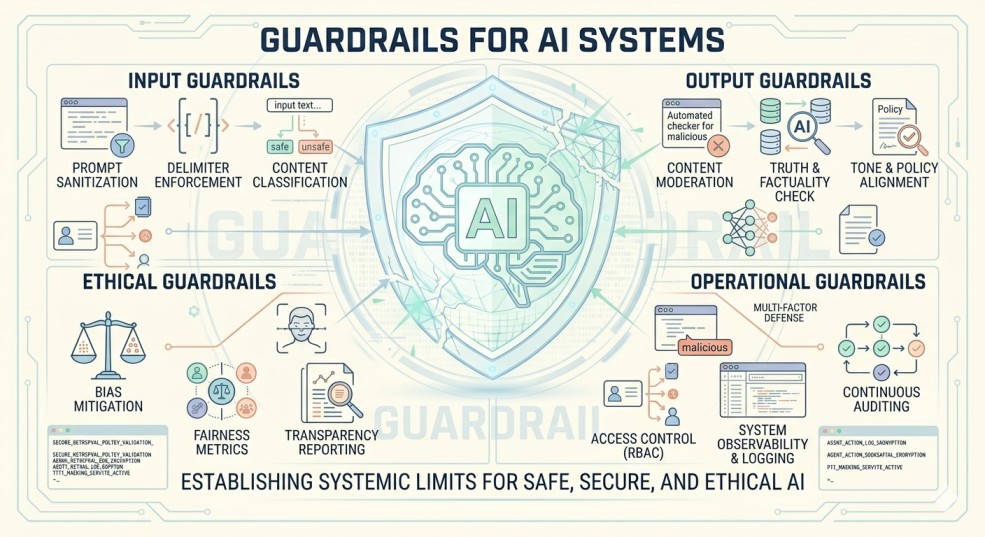
In standard web applications, validation is clear cut—an input either matches a SQL injection regex pattern, or it doesn't. In generative AI and autonomous agentic systems, however, security is deeply contextual. An AI agent can execute a dangerous task not because of a software bug, but because it was politely persuaded to ignore its system instructions by a clever user prompt.
To secure these systems without crippling development speed, engineering teams must move away from treating security as a post-deployment "firewall problem." Instead, a comprehensive safety architecture must inject guardrails across three phases of the AI Software Development Life Cycle (SDLC): Develop-Time, Build-Time, and Runtime.
The 3-Tier AI SDLC Guardrail Framework
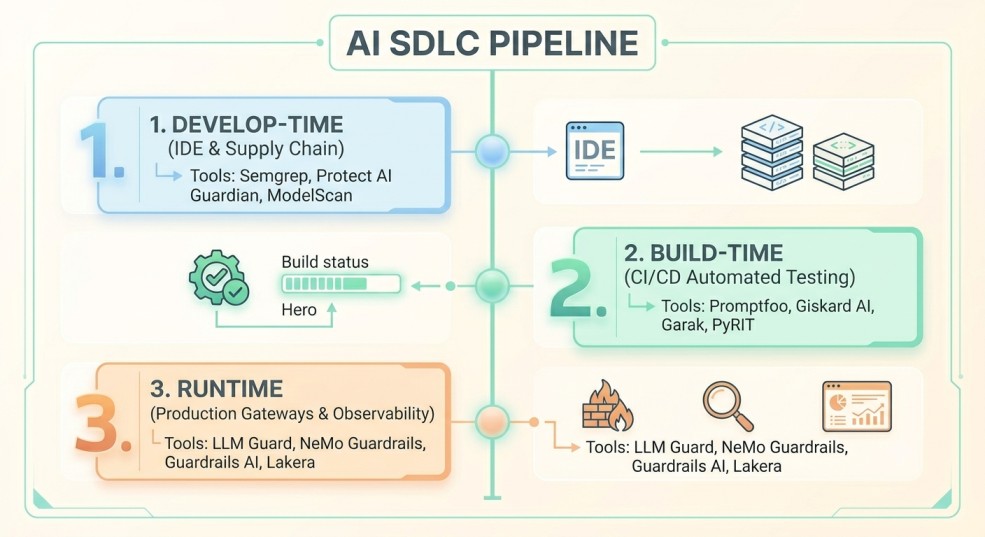
1. Develop-Time Guardrails (IDE & Dependency Phase)
The Goal: Stop insecure prompts, credential leaks, and malicious base models from entering the codebase.
Develop-time guardrails look a lot like traditional SAST, but they are tailored to catch vulnerabilities specific to AI libraries and data science dependencies.
- Protect AI (Guardian & ModelScan) [Open Source / Freemium]: Developers frequently pull pre-trained weights from public repositories like Hugging Face. ModelScan checks these models for embedded serialization attacks (such as malicious pickle files) before they are loaded into local memory.
- Semgrep [Open Source Core]: A lightweight, lightning-fast static analysis tool. By using customized AI and security rulesets, Semgrep stops developers from checking in hardcoded API keys, using vulnerable versions of orchestration libraries (like LangChain or LlamaIndex), or creating insecure data-flow paths to backend databases.
2. Build-Time Guardrails (CI/CD & Pre-Deployment Evaluation)
The Goal: Run automated testing and simulated attacks before code is merged or deployed.
Because an LLM's behavior can drift or react unexpectedly to prompt tweaks, the build stage must dynamically test the model's resilience to exploits like prompt injections, jailbreaks, and unintended data exposure.
- Promptfoo [Open Source]: A standout CLI tool for testing LLM applications natively inside GitHub Actions or GitLab CI/CD. It lets you write declarative test assertions (e.g., "Output must not contain PII" or "Must reject override instructions"). If a developer changes a prompt and it suddenly fails a security assertion, the build breaks.
- Giskard AI [Open Source]: A Python-based testing framework built specifically for evaluating LLMs and autonomous agents. It automatically scans your system for hallucinations, systemic bias, and data leakage during compilation.
- Garak & PyRIT [Open Source]: Garak (the LLM vulnerability scanner) and Microsoft’s PyRIT (Python Risk Identification Tool) act as automated, pre-deployment red-teaming utilities. They programmatically bombard your application with known exploit strategies to find structural breaking points before your users do.
3. Runtime Guardrails (Production Gateway & Observability Layer)
The Goal: Intercept, evaluate, and sanitize real-time user inputs and model outputs in milliseconds.
No testing suite is completely exhaustive. Runtime guardrails serve as an active firewall layer sitting between the application user, the orchestration engine, and the foundational model.
- LLM Guard [Open Source]: Developed by Protect AI, this is an incredibly modular toolkit providing 15+ input scanners (catching prompt injections, banned tokens, or gibberish) and 20+ output scanners (redacting PII, checking for factual consistency, or blocking toxic generation). It runs completely localized and offline without extra per-request vendor costs.
- NVIDIA NeMo Guardrails [Open Source]: Uses an advanced domain-specific scripting language called Colang. It provides precise, programmable orchestration over agent conversations, defining explicit boundaries for conversational themes, handling jailbreak attempts, and validating facts.
- Guardrails AI [Open Source]: A heavily adopted open-source framework that wraps your API calls in specific structure validations (called "guards"). It forces output formats to strictly adhere to schemas while dynamically filtering out restricted data types.
- Lakera Guard [Paid / Enterprise API]: For teams prioritizing operational simplicity over running self-hosted models, Lakera offers an ultra-low-latency, managed security API endpoint designed exclusively to neutralize prompt injections and data exfiltration patterns out of the box.
Choosing Your Starting Point
Building an entirely secure AI application doesn't happen overnight.
If you are a startup prioritizing agility, start by putting Promptfoo in your CI/CD pipeline to lock down prompt regression, and pair it with LLM Guard at runtime to prevent basic data leakage. As your application evolves into complex, multi-agent workflows executing background code or accessing critical databases, look into tools like NeMo Guardrails.